概述
Apache Flume 是一个分布式、高可靠、高可用的用来收集、聚合、转移不同来源的大量日志数据到中央数据仓库的工具。
系统要求
Java运行环境 - Java 1.8或更高版本。
内存 - 足够的内存 用来配置Souces、Channels和Sinks。
硬盘空间 - 足够的硬盘用来配置Channels 和 Sinks。
目录权限 - Agent用来读写目录的权限。
体系结构
Event是Flume定义的一个数据流传输的最小单元。Agent就是一个Flume的实例,本质是一个JVM进程,该JVM进程控制Event数据流从外部日志生产者那里传输到目的地(或者是下一个Agent)。
提示 学习Flume必须明白这几个概念,Event英文直译是事件,但是在Flume里表示数据传输的一个最小单位(被Flume收集的一条条日志又或者一个个的二进制文件,不管你在外面叫什么,进入Flume之后它就叫event)。参照下图可以看得出Agent就是Flume的一个部署实例, 一个完整的Agent中包含了必须的三个组件Source、Channel和Sink,Source是指数据的来源和方式,Channel是一个数据的缓冲池,Sink定义了数据输出的方式和目的地(这三个组件是必须有的,另外还有很多可选的组件interceptor、channel selector、sink processor等后面会介绍。
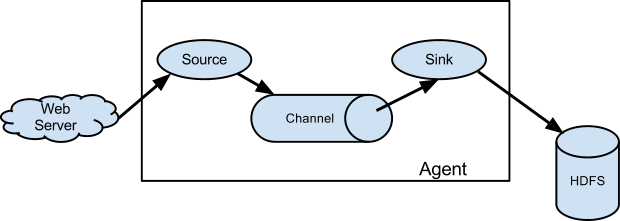
Source消耗由外部(如Web服务器)传递给它的Event。外部以Flume Source识别的格式向Flume发送Event。例如,Avro Source 可接收从Avro客户端(或其他FlumeSink)接收Avro Event。用 Thrift Source 也可以实现类似的流程,接收的Event数据可以是任何语言编写的只要符合Thrift协议即可。
当Source接收Event时,它将其存储到一个或多个channel。该channel是一个被动存储器(或者说叫存储池),可以存储Event直到它被Sink消耗。『文件channel』就是一个例子 - 它由本地文件系统支持。sink从channel中移除Event并将其放入外部存储库(如HDFS,通过 Flume的 HDFS Sink 实现)或将其转发到流中下一个Flume Agent(下一跳)的Flume Source。
Agent中的source和sink与channel存取Event是异步的。
Flume的Source负责消费外部传递给它的数据(比如web服务器的日志)。外部的数据生产方以Flume Source识别的格式向Flume发送Event。
“Source消耗由外部传递给它的Event”,这句话听起来好像Flume只能被动接收Event,实际上Flume也有Source是主动收集Event的,比如:Spooling Directory Source 、Taildir Source 。
复杂流
Flume可以设置多级Agent连接的方式传输Event数据。也支持扇入和扇出的部署方式,类似于负载均衡方式或多点同时备份的方式。
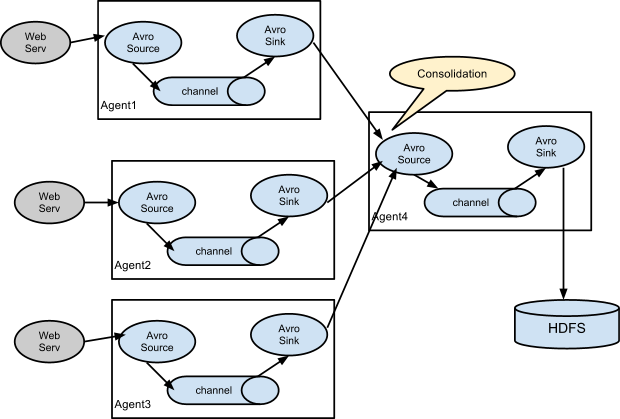
提示 这里必须解释一下,第一句的意思是可以部署多个Agent组成一个数据流的传输链。第二句要知道扇入(多对一)和扇出(一对多)的概念,就是说Agent可以将数据流发到多个下级Agent,也可以从多个Agent发到一个Agent中,就是汇聚和数据发散的意思。 其实他们就是想告诉你,你可以根据自己的业务需求来任意组合传输日志的Agent流,引用一张后面章节的图,这就是一个扇入方式的Flume部署方式,前三个Agent的数据都汇总到一个Agent4上,最后由Agent4统一存储到HDFS。
可靠性
Event会在每个Agent的Channel上进行缓存,随后Event将会传递到流中的下一个Agent或目的地(比如HDFS)。只有成功地发送到下一个Agent或目的地后Event才会从Channel中删除。这一步保证了Event数据流在Flume Agent中传输时端到端的可靠性。
Flume使用事务来保证Event的 可靠传输。Source和Sink对Channel提供的每个Event数据分别封装一个事务用于存储和恢复,这样就保证了数据流的集合在点对点之间的可靠传输。在多层架构的情况下,来自前一层的sink和来自下一层的Source 都会有事务在运行以确保数据安全地传输到下一层的Channel中。
可恢复性
Event数据会缓存在Channel中用来在失败的时候恢复出来。Flume支持保存在本地文件系统中的『文件channel』,也支持保存在内存中的『内存Channel』,『内存Channel』显然速度会更快,缺点是万一Agent挂掉『内存Channel』中缓存的数据也就丢失了。
多路复用流
lume支持多路复用数据流到一个或多个目的地。这是通过使用一个流的[多路复用器](multiplexer)来实现的,它可以 复制 或者 选择(多路复用) 数据流到一个或多个channel上。
提示 很容易理解, 复制 就是每个channel的数据都是完全一样的,每一个channel上都有完整的数据流集合。 选择(多路复用) 就是通过自定义一个分配机制,把数据流拆分到多个channel上。后面有详细介绍,请参考 Flume Channel Selectors 。
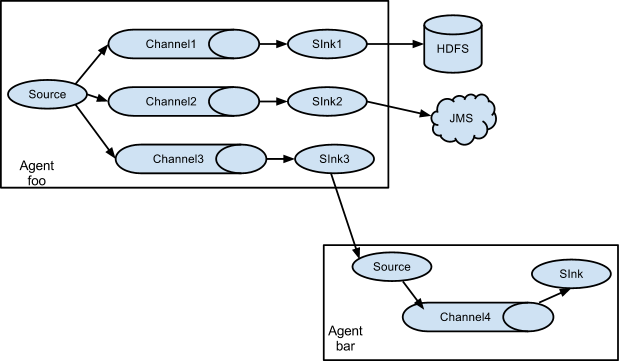
上图的例子展示了从Agent foo扇出流到多个channel中。这种扇出的机制可以是 复制 或者 选择(多路复用) 。当配置为复制的时候,每个Event都会被发送到3个channel上。当配置为选择(多路复用)的时候,当Event的某个属性与配置的值相匹配时会被发送到对应的channel。
例如Event的属性txnType是customer时,Event被发送到channel1和channel3,如果txnType的值是vendor时,Event被发送到channel2,其他值一律发送到channel3,这种规则是可以通过配置来实现的。
Source、Sink组件的 batchSizes与channel的单个事务容量兼容要求
基本上Source和Sink都可以配置batchSize来指定一次事务写入/读取的最大event数量,对于有event容量上限的Channel来说,这个batchSize必须要小于这个上限。
Flume只要读取配置,就会检查这个数量设置是否合理以防止设置不兼容。
看发布日志具体指的是文件Channel( File Channel )和内存Channel( Memory Channel ),Source和Sink的配置的batchSize数量不应该超过channel中配置的transactionCapacity。
flume中文手册